추출하려는 데이터 프레임 이름 뒤에 []를 입력한 다음 추출할 변수명을 따옴표로 감싸서 입력
#exam에서 변수 추출
exam[['nclass','english','math']] #'nclass','english','math'만 추출
exam[['math']] #'math' 하나만 추출해도 데이터 프레임 유지 가능([]아니면 시리즈로 추출)#변수 제거
exam.drop(columns='math') #'math'제거
exam.drop(columns=['math','english']) #'math','english' 제거#pandas 함수와 함께 사용
exam.query('nclass==1')['english'] #nclass가 1인 행만 추출하고 english 추출
exam.query('math>=50')[['id','math']] #math가 50이상인 행만 추출한 다음 id,math 추출
가독성 있게 줄 바꾸기
명령어 끝난 부분 뒤에 백슬래시(\) 입력 후 엔터로 줄바꿈
백슬래시 뒤에는 주석이나 띄어쓰기 무엇도 쓰면 안됨
#백슬래시 이용 코드
exam.query('math>=50') \
[['id','math']] \
.head(10)
#total 변수 추가
exam.assign(total=exam['math']+exam['english']+exam['science'])
#여러 파생변수 한 번에 추가하기
exam.assign(
total=exam['math']+exam['english']+exam['science'],
mean = (exam['math']+exam['english']+exam['science'])/3)
#assign에 where 적용하기
exam.assign(test = np.where(exam['science']>=60,'pass','fail'))
#total 변수를 추가하고 total 기준 정렬
exam.assign(total=exam['math']+exam['english']+exam['science']) \
.sort_values('total',ascending=False)
#lambda 이용해 데이터 프레임명 줄여쓰기(데이터 프레임명을 약어로 입력)
exam.assign(total=lambda x: x['math']+x['english']+x['science'],
mean= lambda x: x['total']/3)
집단별로 요약하기: df.groupby(), df.agg()
.agg()에서 자주 사용하는 요약통계량 함수
mean(): 평균
std(): 표준편차
sum(): 합계
median(): 중앙값
min(): 최소값
max(): 최대값
count(): 빈도(개수)
#math 평균
exam.agg(mean_math=('math','mean'))
#집단별 요약통계량
exam.groupby('nclass') \
.agg(mean_math = ('math','mean'))
#변수를 인덱스로 바꾸지 않기(as_index = False)
exam.groupby('nclass',as_index = False) \
.agg(mean_math = ('math','mean'))
#여러 요약통계량 한번에 구하기
exam.groupby('nclass', as_index=False)\
.agg(mean_math=('math','mean'),
sum_math=('math','sum'),
median_mat=('math','median'),
n=('math','count'))
#모든 변수의 요약통계량 한번에 보기 df.agg()대신 요약통계량 함수 사용
exam.groupby('nclass', as_index=False).mean()
집단별로 다시 나누기
#집단을 나눈 다음 다시 하위집단으로 나누기
mpg.groupby(['manufacturer','drv'])\
.agg(mean_cty=('cty','mean'))
#value_counts()로 집단별 빈도 간단하게 구하기#짧은 코드로 빈도를 구할 수 있으며 자동으로 내림차순 정렬#출력 결과가 데이터프레임이 아닌 시리즈 구조로 query()적용 불가
mpg.groupby('drv').agg(n=('drv','count'))
mpg['drv'].value_counts()
데이터 합치기
가로로 합치기: df.merge()
세로로 합치기: df.concat()
#가로로 합치기#중간고사 데이터
test1 = pd.DataFrame({ "id" : [1,2,3,4,5],
"midterm" : [60,80,70,90,85]})
#기말고사 데이터
test2 = pd.DataFrame({ "id" : [1,2,3,4,5],
"final" : [70,83,65,95,80]})
#id기준으로 합쳐서 total에 할당
total=pd.merge(test1,test2,how='left',on='id')
#다른 데이터를 활용해 변수 추가하기
name = pd.DataFrame({"nclass" : [1,2,3,4,5],
"teacher": ["kim", "lee", "park", "choi", "jung"]})
#nclass기준으로 합쳐서 exam_new에 할당
exam_new=pd.merge(exam,name,how='left',on='nclass')
#세로로 합치기#학생 1~5번 시험 데이터
group_a = pd.DataFrame({"id": [1,2,3,4,5],
"test" : [60,80,70,90,85]})
#학생 6~10
group_b = pd.DataFrame({"id": [6,7,8,9,10],
"test" : [60,80,70,90,85]})
#인덱스가 중복 안되도록 새로 부여하려면 concat()에 ignore_index=True
group_all = pd.concat([group_a,group_b],ignore_index=True)
결측치(missing value)
누락된 값, 비어있는 값
데이터 수집 과정에서 발생한 오류로 포함될 가능성
함수가 적용되지 않거나 분석결과가 왜곡되는 문제가 발생
실제 데이터 분석시 결측치 확인, 제거 후 분석해야 함
pd.mean()과 pd.sum()은 결측치를 자동으로 제거하고 연산
groupby(),agg()도 결측치를 제거하고 연산
#결측치 확인
pd.isna(df)
#결측치 빈도 확인
pd.isna(df).sum()
#결측치 있는 행 제거
df.dropna(subset=['score']) #score 결측치 제거(행 전체)#여러변수에 결측지 없는 데이터 추출하기
df_nomiss=df.dropna(subset=['score','sex'])
#결측치가 하나라도 있으면 제거
df_nomiss2=df.dropna()
결측치 대체하기
결측치가 적고 데이터가 크면 결측치를 제거 후 분석 가능
데이터가 작고 결측치가 많으면 데이터 손실로 분석결과에 왜곡이 발생
결측치 대체법: 결측치를 제거하는 대신 다른 값을 채워 넣는 방법
대표값(평균값, 최빈값 등)을 구해 일괄 대체
통계 분석 기법으로 결측치의 예측값 추정 후 대체
#평균값으로 결측지 대체#결측치 생성
exam=pd.read_csv('exam.csv')
exam.loc[[2,7,14],['math']] = np.nan
#평균값 구하기
exam['math'].mean()
#df.fillna()로 결측치 대체
exam['math']=exam['math'].fillna(55)
#결측치 빈도 확인
exam['math'].isna().sum()
이상치(anomaly) : 정상 범위에서 크게 벗어난 값
실제 데이터에 대부분 이상치가 들어있음
제거하지 않으면 분석결과가 왜곡되므로 분석 전에 제거 작업이 필요
논리적으로 존재할 수 없는 값이 있을 경우 결측치로 변환 후 제거
#이상치가 들어있는 데이터 만들기
df = pd.DataFrame({'sex': [1, 2, 1, 3, 2, 1],
'score' : [5, 4, 3, 4, 2, 6]})
#빈도표를 만들어 존재할 수 없는 값이 있는지 확인
df['sex'].value_counts(sort=False).sort_index()
df['score'].value_counts(sort=False).sort_index()
#이상치일 경우 NaN 부여
df['sex']=np.where(df['sex']==3, np.nan, df['sex'])
df['score']=np.where(df['score']>5,np.nan,df['score'])
#결측치 제거 후 분석
df.dropna(subset=['sex','score'])\
.groupby('sex')\
.agg(mean_score=('score','mean'))
np.where()를 사용할 때 반환 값 중 문자가 있으면 np.nan으로 지정해도 문자 'nan'을 반환(nan은 결측치로 인식X)
#변수를 문자와 NaN으로 함께 구성하는 방법#결측치로 만들 값에 문자 부여
df['x2']=np.where(df['x1']==1,'a','etc')
#etc를 NaN으로 바꾸기
df['x2']=df['x2'].replace('etc',np.nan)
극단치(Outlier): 논리적으로 존재할 수 있지만 극단적으로 크거나 작은 값
극단치가 존재할 경우 분석 결과 왜곡
기준
논리적 판단
통계적 기준(ex: 상하위 0.3% 또는 3 표준편차만큼 벗어나는 값)
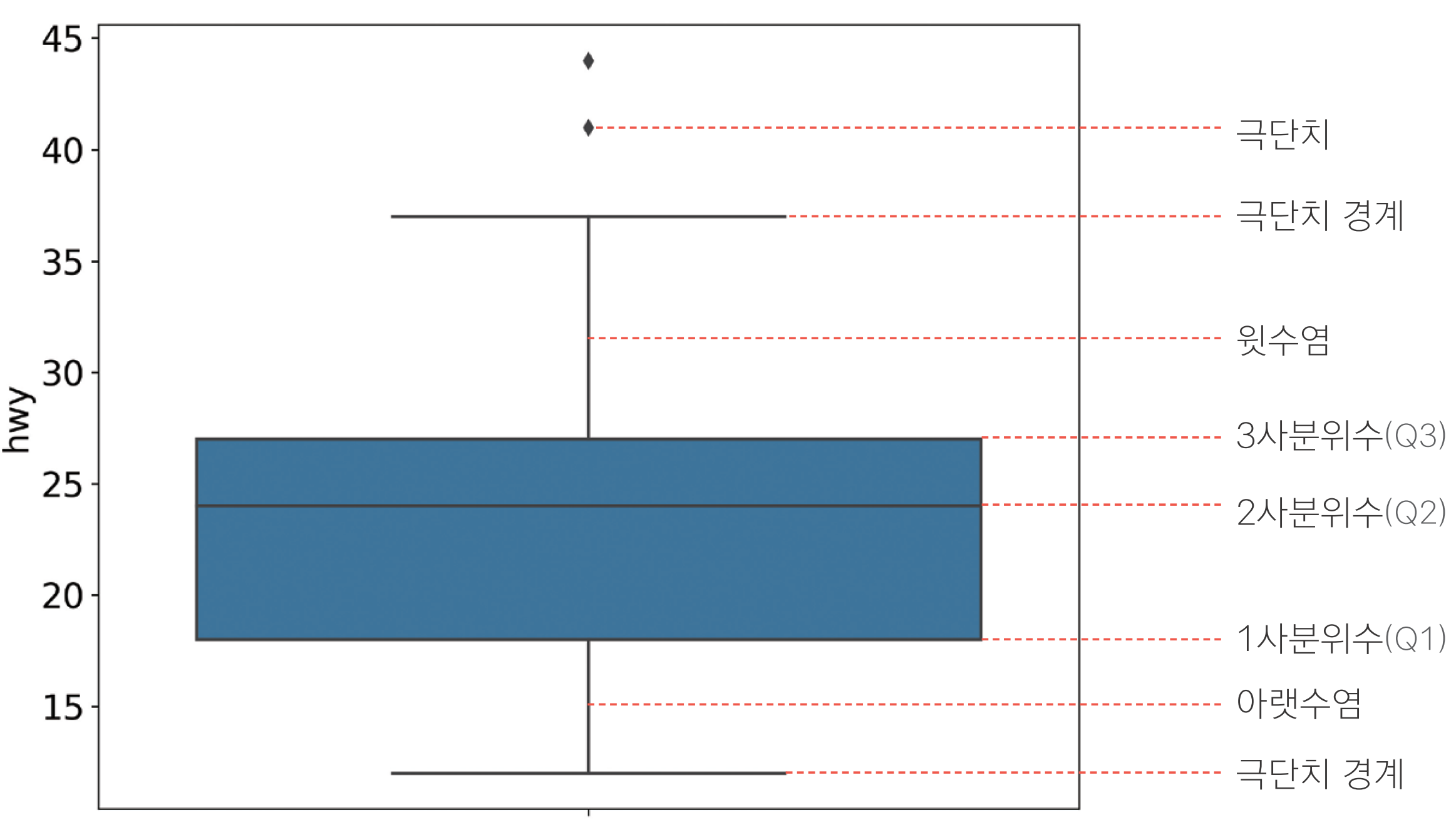
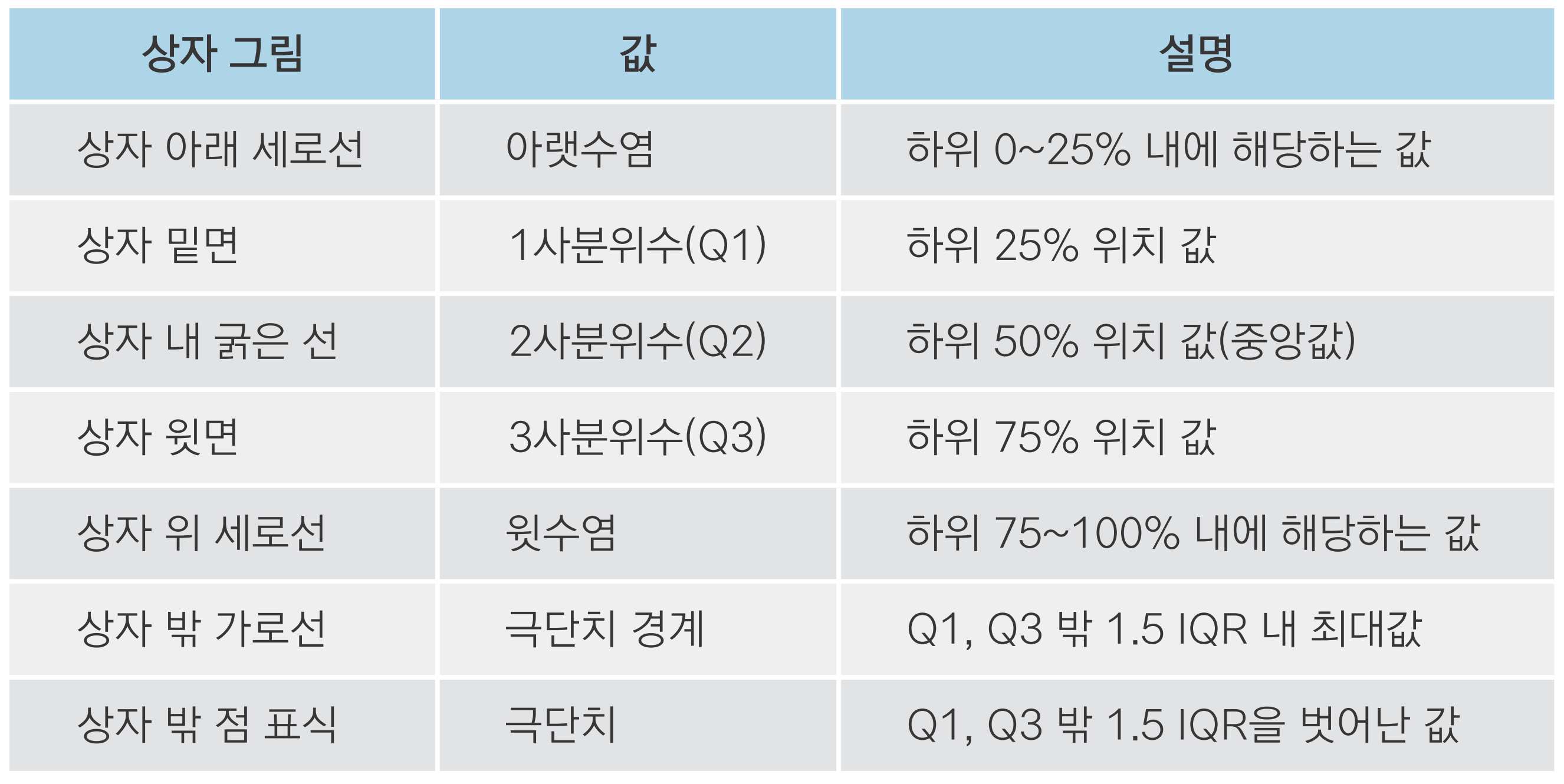
상자그림(box plot)을 이용해 중심에서 크게 벗어난 값을 극단치로 간주
상자 그림(box plot): 데이터의 분포를 상자 모양으로 표현한 그래프(극단치 기준을 구할 수 있음)
box plot
#1사분위수, 3사분위수 구하기
pct25=mpg['hwy'].quantile(.25)
pct75=mpg['hwy'].quantile(.75)
#IQR 구하기
iqr = pct75 - pct25
#하한,상한 구하기
pct25-1.5*iqr #하한
pct75+1.5*iqr #상한#4.5~40.5 벗어나면 NaN 부여
mpg['hwy']=np.where((mpg['hwy']<4.5)|(mpg['hwy']>40.5),np.nan,mpg['hwy'])
#결측치 빈도 확인
mpg['hwy'].isna().sum()
#결측치를 제거하고 분석
mpg.dropna(subset=['hwy'])\
.groupby('drv')\
.agg(mean_hwy=('hwy','mean'))